 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Image Coding for Humans and Machines
Papers and Code
Progressive Learned Image Compression for Machine Perception
Dec 23, 2025Recent advances in learned image codecs have been extended from human perception toward machine perception. However, progressive image compression with fine granular scalability (FGS)-which enables decoding a single bitstream at multiple quality levels-remains unexplored for machine-oriented codecs. In this work, we propose a novel progressive learned image compression codec for machine perception, PICM-Net, based on trit-plane coding. By analyzing the difference between human- and machine-oriented rate-distortion priorities, we systematically examine the latent prioritization strategies in terms of machine-oriented codecs. To further enhance real-world adaptability, we design an adaptive decoding controller, which dynamically determines the necessary decoding level during inference time to maintain the desired confidence of downstream machine prediction. Extensive experiments demonstrate that our approach enables efficient and adaptive progressive transmission while maintaining high performance in the downstream classification task, establishing a new paradigm for machine-aware progressive image compression.
Explicit Residual-Based Scalable Image Coding for Humans and Machines
Jun 24, 2025Scalable image compression is a technique that progressively reconstructs multiple versions of an image for different requirements. In recent years, images have increasingly been consumed not only by humans but also by image recognition models. This shift has drawn growing attention to scalable image compression methods that serve both machine and human vision (ICMH). Many existing models employ neural network-based codecs, known as learned image compression, and have made significant strides in this field by carefully designing the loss functions. In some cases, however, models are overly reliant on their learning capacity, and their architectural design is not sufficiently considered. In this paper, we enhance the coding efficiency and interpretability of ICMH framework by integrating an explicit residual compression mechanism, which is commonly employed in resolution scalable coding methods such as JPEG2000. Specifically, we propose two complementary methods: Feature Residual-based Scalable Coding (FR-ICMH) and Pixel Residual-based Scalable Coding (PR-ICMH). These proposed methods are applicable to various machine vision tasks. Moreover, they provide flexibility to choose between encoder complexity and compression performance, making it adaptable to diverse application requirements. Experimental results demonstrate the effectiveness of our proposed methods, with PR-ICMH achieving up to 29.57% BD-rate savings over the previous work.
ABC: Adaptive BayesNet Structure Learning for Computational Scalable Multi-task Image Compression
Jun 18, 2025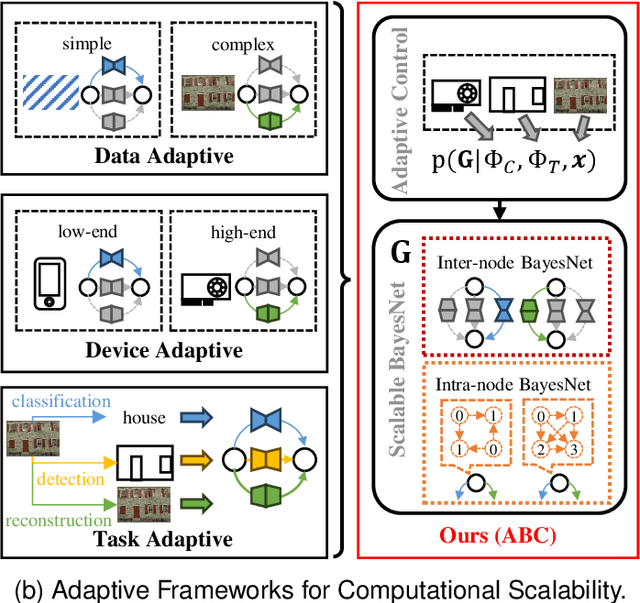

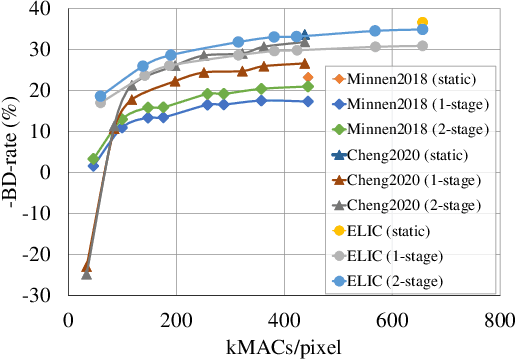
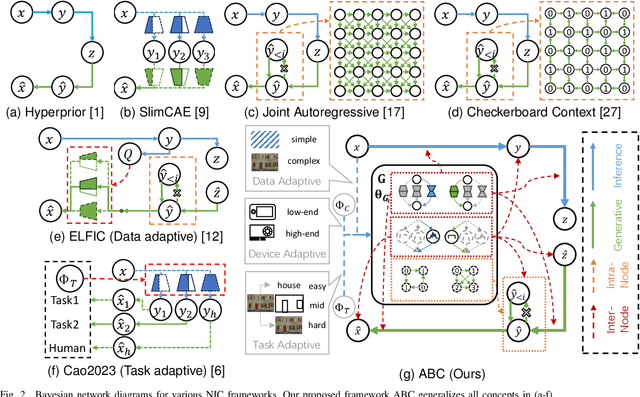
Neural Image Compression (NIC) has revolutionized image compression with its superior rate-distortion performance and multi-task capabilities, supporting both human visual perception and machine vision tasks. However, its widespread adoption is hindered by substantial computational demands. While existing approaches attempt to address this challenge through module-specific optimizations or pre-defined complexity levels, they lack comprehensive control over computational complexity. We present ABC (Adaptive BayesNet structure learning for computational scalable multi-task image Compression), a novel, comprehensive framework that achieves computational scalability across all NIC components through Bayesian network (BayesNet) structure learning. ABC introduces three key innovations: (i) a heterogeneous bipartite BayesNet (inter-node structure) for managing neural backbone computations; (ii) a homogeneous multipartite BayesNet (intra-node structure) for optimizing autoregressive unit processing; and (iii) an adaptive control module that dynamically adjusts the BayesNet structure based on device capabilities, input data complexity, and downstream task requirements. Experiments demonstrate that ABC enables full computational scalability with better complexity adaptivity and broader complexity control span, while maintaining competitive compression performance. Furthermore, the framework's versatility allows integration with various NIC architectures that employ BayesNet representations, making it a robust solution for ensuring computational scalability in NIC applications. Code is available in https://github.com/worldlife123/cbench_BaSIC.
Draw with Thought: Unleashing Multimodal Reasoning for Scientific Diagram Generation
Apr 13, 2025Scientific diagrams are vital tools for communicating structured knowledge across disciplines. However, they are often published as static raster images, losing symbolic semantics and limiting reuse. While Multimodal Large Language Models (MLLMs) offer a pathway to bridging vision and structure, existing methods lack semantic control and structural interpretability, especially on complex diagrams. We propose Draw with Thought (DwT), a training-free framework that guides MLLMs to reconstruct diagrams into editable mxGraph XML code through cognitively-grounded Chain-of-Thought reasoning. DwT enables interpretable and controllable outputs without model fine-tuning by dividing the task into two stages: Coarse-to-Fine Planning, which handles perceptual structuring and semantic specification, and Structure-Aware Code Generation, enhanced by format-guided refinement. To support evaluation, we release Plot2XML, a benchmark of 247 real-world scientific diagrams with gold-standard XML annotations. Extensive experiments across eight MLLMs show that our approach yields high-fidelity, semantically aligned, and structurally valid reconstructions, with human evaluations confirming strong alignment in both accuracy and visual aesthetics, offering a scalable solution for converting static visuals into executable representations and advancing machine understanding of scientific graphics.
Toward Scalable Image Feature Compression: A Content-Adaptive and Diffusion-Based Approach
Oct 08, 2024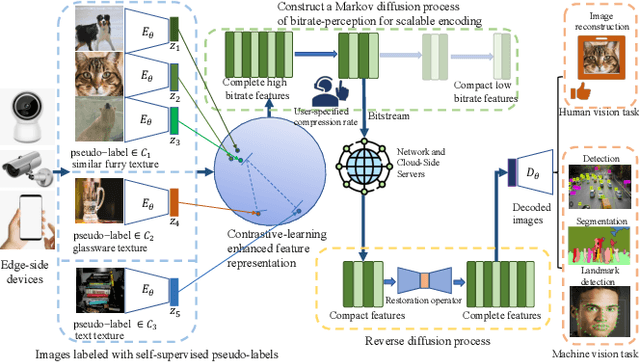
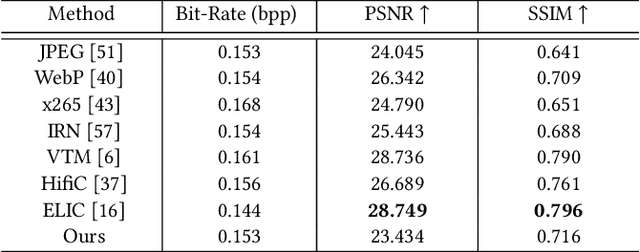

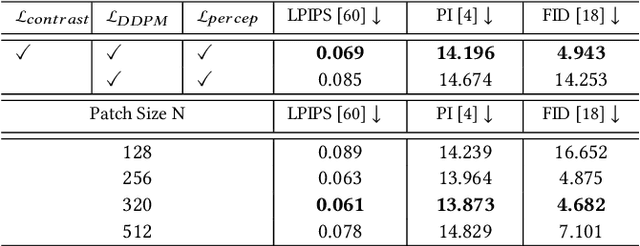
Traditional image codecs emphasize signal fidelity and human perception, often at the expense of machine vision tasks. Deep learning methods have demonstrated promising coding performance by utilizing rich semantic embeddings optimized for both human and machine vision. However, these compact embeddings struggle to capture fine details such as contours and textures, resulting in imperfect reconstructions. Furthermore, existing learning-based codecs lack scalability. To address these limitations, this paper introduces a content-adaptive diffusion model for scalable image compression. The proposed method encodes fine textures through a diffusion process, enhancing perceptual quality while preserving essential features for machine vision tasks. The approach employs a Markov palette diffusion model combined with widely used feature extractors and image generators, enabling efficient data compression. By leveraging collaborative texture-semantic feature extraction and pseudo-label generation, the method accurately captures texture information. A content-adaptive Markov palette diffusion model is then applied to represent both low-level textures and high-level semantic content in a scalable manner. This framework offers flexible control over compression ratios by selecting intermediate diffusion states, eliminating the need for retraining deep learning models at different operating points. Extensive experiments demonstrate the effectiveness of the proposed framework in both image reconstruction and downstream machine vision tasks such as object detection, segmentation, and facial landmark detection, achieving superior perceptual quality compared to state-of-the-art methods.
Refining Coded Image in Human Vision Layer Using CNN-Based Post-Processing
May 20, 2024Scalable image coding for both humans and machines is a technique that has gained a lot of attention recently. This technology enables the hierarchical decoding of images for human vision and image recognition models. It is a highly effective method when images need to serve both purposes. However, no research has yet incorporated the post-processing commonly used in popular image compression schemes into scalable image coding method for humans and machines. In this paper, we propose a method to enhance the quality of decoded images for humans by integrating post-processing into scalable coding scheme. Experimental results show that the post-processing improves compression performance. Furthermore, the effectiveness of the proposed method is validated through comparisons with traditional methods.
T2Vs Meet VLMs: A Scalable Multimodal Dataset for Visual Harmfulness Recognition
Sep 29, 2024



To address the risks of encountering inappropriate or harmful content, researchers managed to incorporate several harmful contents datasets with machine learning methods to detect harmful concepts. However, existing harmful datasets are curated by the presence of a narrow range of harmful objects, and only cover real harmful content sources. This hinders the generalizability of methods based on such datasets, potentially leading to misjudgments. Therefore, we propose a comprehensive harmful dataset, Visual Harmful Dataset 11K (VHD11K), consisting of 10,000 images and 1,000 videos, crawled from the Internet and generated by 4 generative models, across a total of 10 harmful categories covering a full spectrum of harmful concepts with nontrivial definition. We also propose a novel annotation framework by formulating the annotation process as a multi-agent Visual Question Answering (VQA) task, having 3 different VLMs "debate" about whether the given image/video is harmful, and incorporating the in-context learning strategy in the debating process. Therefore, we can ensure that the VLMs consider the context of the given image/video and both sides of the arguments thoroughly before making decisions, further reducing the likelihood of misjudgments in edge cases. Evaluation and experimental results demonstrate that (1) the great alignment between the annotation from our novel annotation framework and those from human, ensuring the reliability of VHD11K; (2) our full-spectrum harmful dataset successfully identifies the inability of existing harmful content detection methods to detect extensive harmful contents and improves the performance of existing harmfulness recognition methods; (3) VHD11K outperforms the baseline dataset, SMID, as evidenced by the superior improvement in harmfulness recognition methods. The complete dataset and code can be found at https://github.com/nctu-eva-lab/VHD11K.
Scalable Face Image Coding via StyleGAN Prior: Towards Compression for Human-Machine Collaborative Vision
Dec 25, 2023



The accelerated proliferation of visual content and the rapid development of machine vision technologies bring significant challenges in delivering visual data on a gigantic scale, which shall be effectively represented to satisfy both human and machine requirements. In this work, we investigate how hierarchical representations derived from the advanced generative prior facilitate constructing an efficient scalable coding paradigm for human-machine collaborative vision. Our key insight is that by exploiting the StyleGAN prior, we can learn three-layered representations encoding hierarchical semantics, which are elaborately designed into the basic, middle, and enhanced layers, supporting machine intelligence and human visual perception in a progressive fashion. With the aim of achieving efficient compression, we propose the layer-wise scalable entropy transformer to reduce the redundancy between layers. Based on the multi-task scalable rate-distortion objective, the proposed scheme is jointly optimized to achieve optimal machine analysis performance, human perception experience, and compression ratio. We validate the proposed paradigm's feasibility in face image compression. Extensive qualitative and quantitative experimental results demonstrate the superiority of the proposed paradigm over the latest compression standard Versatile Video Coding (VVC) in terms of both machine analysis as well as human perception at extremely low bitrates ($<0.01$ bpp), offering new insights for human-machine collaborative compression.
Insect Identification in the Wild: The AMI Dataset
Jun 18, 2024
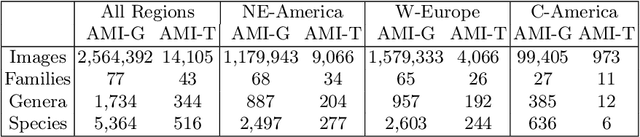


Insects represent half of all global biodiversity, yet many of the world's insects are disappearing, with severe implications for ecosystems and agriculture. Despite this crisis, data on insect diversity and abundance remain woefully inadequate, due to the scarcity of human experts and the lack of scalable tools for monitoring. Ecologists have started to adopt camera traps to record and study insects, and have proposed computer vision algorithms as an answer for scalable data processing. However, insect monitoring in the wild poses unique challenges that have not yet been addressed within computer vision, including the combination of long-tailed data, extremely similar classes, and significant distribution shifts. We provide the first large-scale machine learning benchmarks for fine-grained insect recognition, designed to match real-world tasks faced by ecologists. Our contributions include a curated dataset of images from citizen science platforms and museums, and an expert-annotated dataset drawn from automated camera traps across multiple continents, designed to test out-of-distribution generalization under field conditions. We train and evaluate a variety of baseline algorithms and introduce a combination of data augmentation techniques that enhance generalization across geographies and hardware setups. Code and datasets are made publicly available.
A Comprehensive Survey for Hyperspectral Image Classification: The Evolution from Conventional to Transformers
May 09, 2024



Hyperspectral Image Classification (HSC) is a challenging task due to the high dimensionality and complex nature of Hyperspectral (HS) data. Traditional Machine Learning approaches while effective, face challenges in real-world data due to varying optimal feature sets, subjectivity in human-driven design, biases, and limitations. Traditional approaches encounter the curse of dimensionality, struggle with feature selection and extraction, lack spatial information consideration, exhibit limited robustness to noise, face scalability issues, and may not adapt well to complex data distributions. In recent years, Deep Learning (DL) techniques have emerged as powerful tools for addressing these challenges. This survey provides a comprehensive overview of the current trends and future prospects in HSC, focusing on the advancements from DL models to the emerging use of Transformers. We review the key concepts, methodologies, and state-of-the-art approaches in DL for HSC. We explore the potential of Transformer-based models in HSC, outlining their benefits and challenges. We also delve into emerging trends in HSC, as well as thorough discussions on Explainable AI and Interoperability concepts along with Diffusion Models (image denoising, feature extraction, and image fusion). Lastly, we address several open challenges and research questions pertinent to HSC. Comprehensive experimental results have been undertaken using three HS datasets to verify the efficacy of various conventional DL models and Transformers. Finally, we outline future research directions and potential applications that can further enhance the accuracy and efficiency of HSC. The Source code is available at \href{https://github.com/mahmad00/Conventional-to-Transformer-for-Hyperspectral-Image-Classification-Survey-2024}{github.com/mahmad00}.